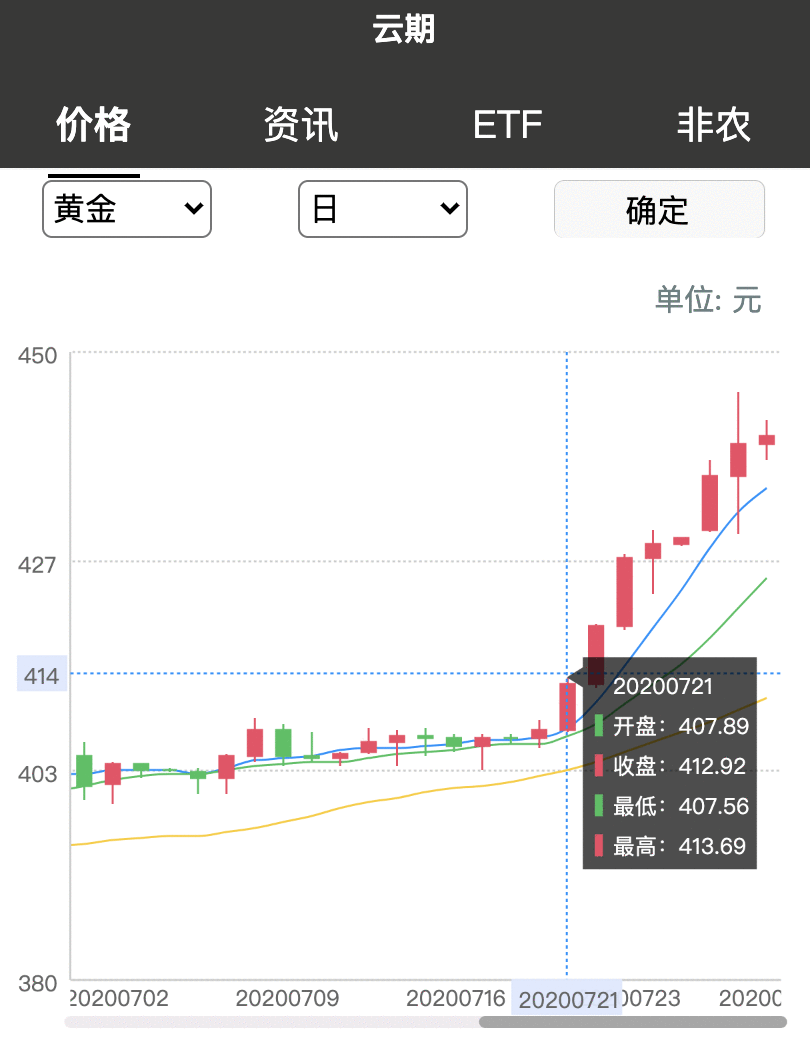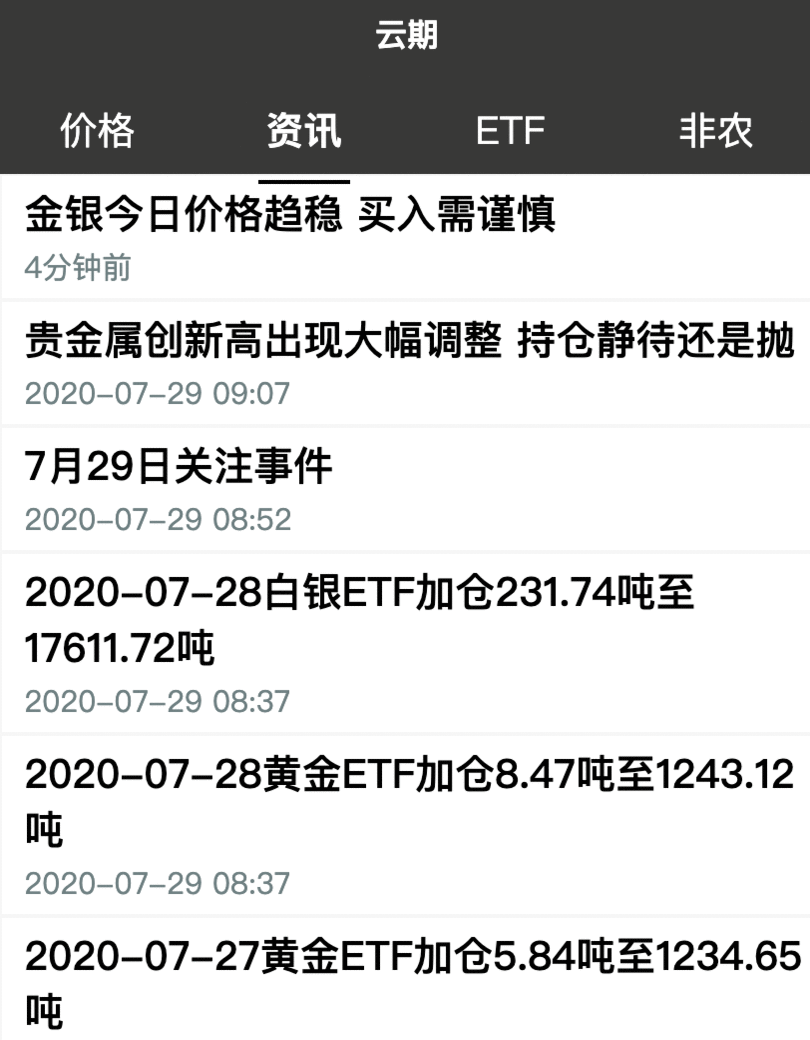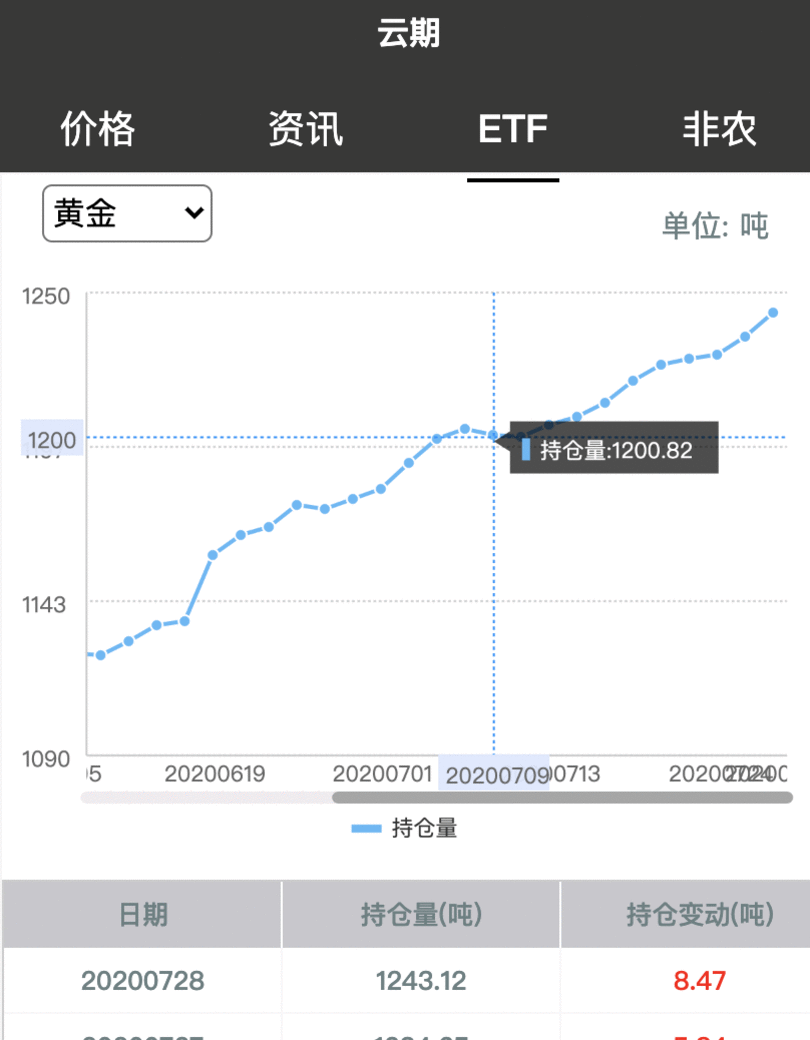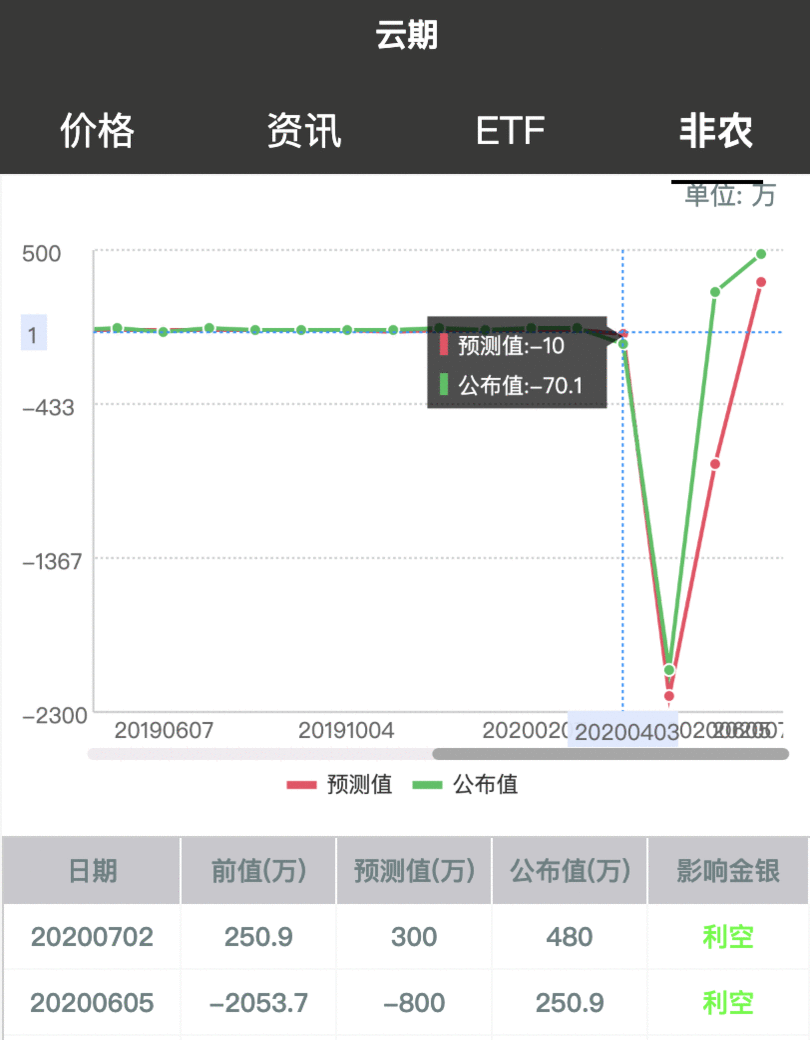
引言
我的博客:https://yunsonbai.top/2017/11/25/redis-mysql/index.html
距离上一篇文章已经有好长一段时间的时间没有共享过新的文章了,这段时间一直忙于处理工作和生活上的事儿,在这里分享一篇工作以来在MySQL和redis(当然缓存还有其他很多个产品,我们本次以redis为例)使用过程中总结的经验,希望对于刚刚开始工作的同学能有一定的帮助作用。这篇文章以MySQL和redis为例。
为什么会用到缓存
在我上学的时候比较流行的说法是LAMP(Linux+Apache+MySQL+PHP)或者是LNMP(Linux+Nginx+MySQL+PHP),那时候基本上会了这四个技术就能写一个简单的web网页(当然还需要会些html)出来,很简单。但是这种系统能承载的量是很低的,尤其在涉及到多次数据库查询的时候会显得异常的慢,因为毕竟MySQL的操作是读取硬盘上的数据,当然你可以采用添加索引、改变存储结构等方式去提升速度,但终归的瓶颈还会被磁盘io限制住。这时的解决方案之一就是利用缓存来解决像redis这中存储系统绝大部分操作是内存上的,读速度上10万/s,写的速度也要近10万/s,当然这个测试受压测机器和服务机器的性能限制,这对于那些qps在大几千的业务线来讲是很具诱惑力的,下边我举几个案例。
记录按钮点击数
只使用MySQL
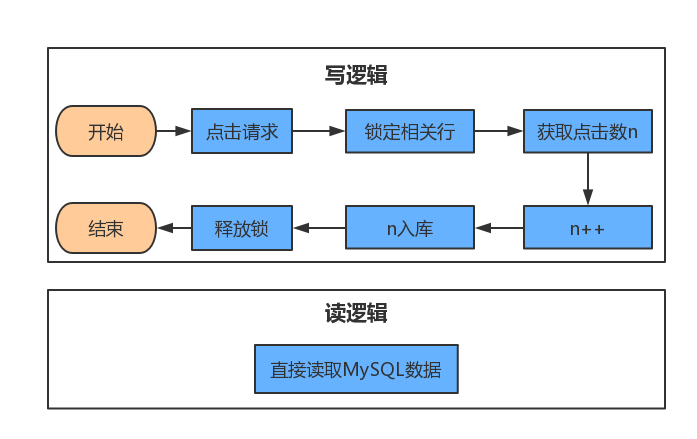
解释说明
使用这个逻辑很容易能解决需求,一旦出现并发,这个”数据库上锁(行锁)“就会直接造成后续的用户等待,只有当其前边的用户操作完,才能轮到自己操作,试想一下如果这是个推广项目将带来多少的用户流失。可以用redis的incr方法解决这个问题。只使用redis
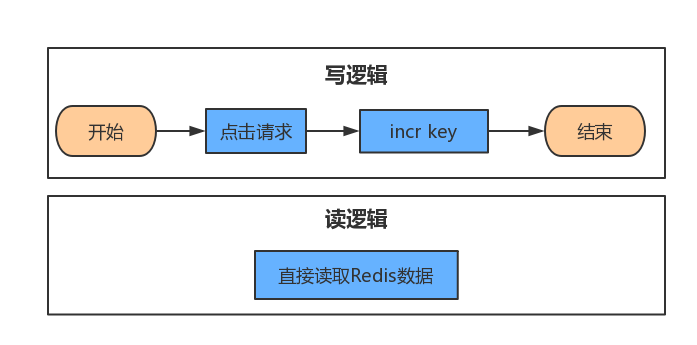
解释说明
这个逻辑很简单,注意这个key是和要访问的资源一一对应的。因为redis是单线程逻辑,而且是内存操作,处理上千的并发问题不大,这样即便同时有很多人同时也能表现的非常流畅。但是这个逻辑有个很脆弱的地方,一旦redis挂了,那数据就全丢了,这个问题很严重。同时使用mysql和redis
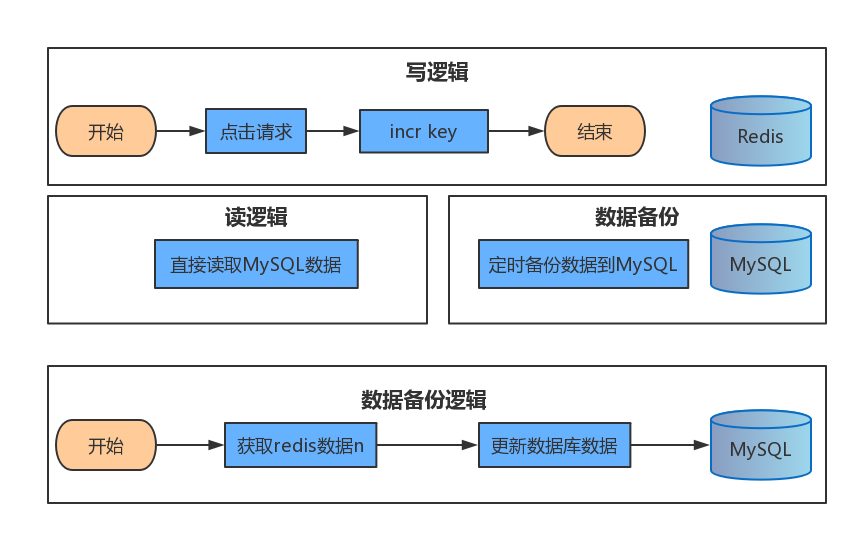
解释说明
现在这个逻辑总的来说就是用redis抗量,MySQL用作数据备份。关于定时任务可以用celery去做。但是这个数据备份逻辑有个很明显的问题:一旦redis数据因异常丢失,这时候在直接写到库里这将是灾难的,数据将失去意义。原因在于这个逻辑采用了用Redis去记录历史数据,这是很糟糕的设计方式。同时使用mysql和redis优化版
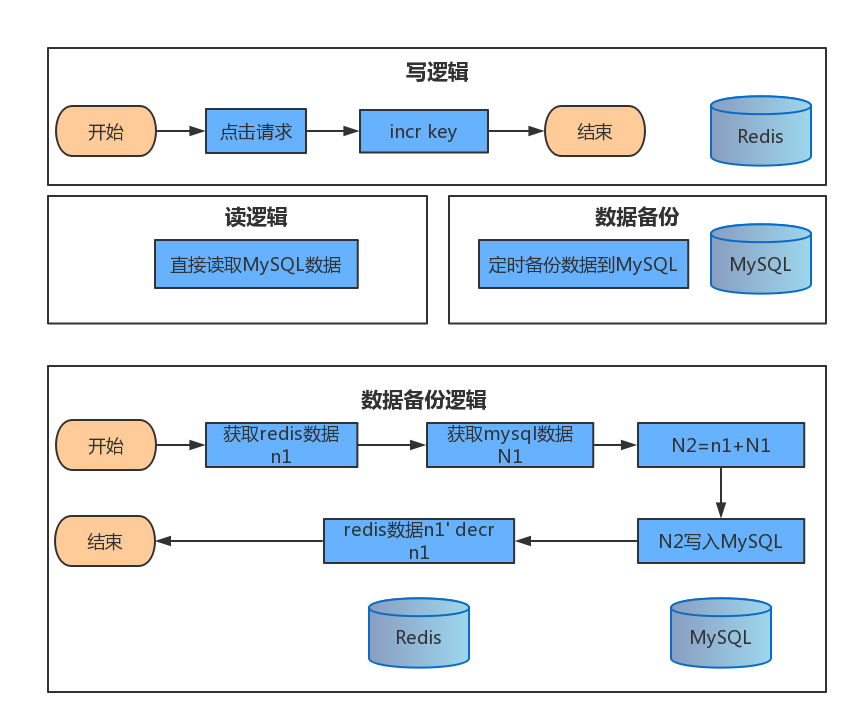
解释说明
当然这个逻辑还是用redis抗量,MySQL用作数据备份。关于定时任务可以用celery去做。但是有个不同的点是,我们不在用redis去记录历史数据,而是利用incr和decr两个函数去实现记录数据增量,那么即便数据有丢失也只是影响异步任务时间段内的数据,不会造成大面积的数据异常,另外还可以优化两点:1是在decr处,如果发现decr的结果是小于0(毕竟△t内的数据增量不会是负数)的数直接记录成0;2是我们可以每次不覆盖MySQL数据而是记录增量来具体观察那个时间段的增速快。
缓存热数据
只使用MySQL
解释说明
逻辑很简单,直接读取数据库数据展示给用户,当并发量较大的时候,我们可以利用索引来解决问题,但是并发量再次增大或者数据量比较复杂不好建立索引或者关联表太多的时候查询数据库将变得异常的慢。利用redis缓存提高并发
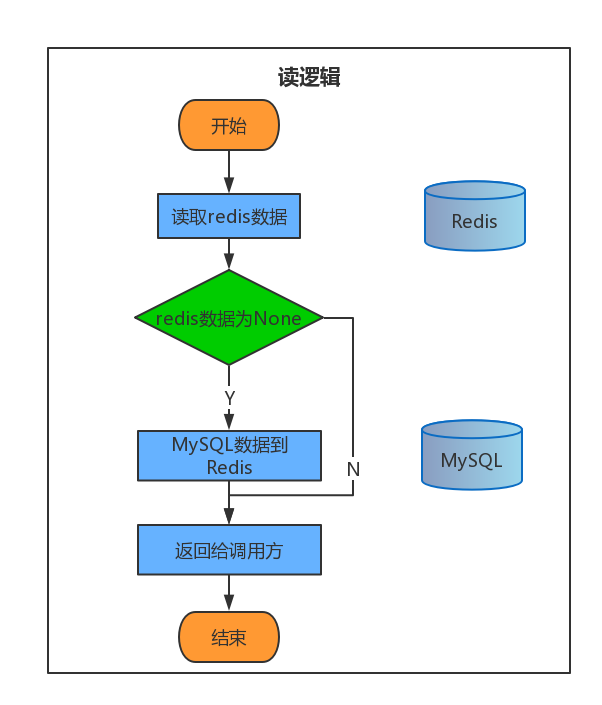
解释说明
对于多表联合查询如果是直接查库的话效率低下,严重影响系统的响应速度,尤其是像查询用户属性这种核心数据的时候,如果是几个业务线都需要查询用户数据,那负责提供用户信息的服务面临的并发会很大上,我们这边有个关于用户查询的接口最大的时候并发能上大几千,这时候光靠数据库可是不行,于是就要上缓存了。像当前这个就是”热数据“缓存到redis中,一般在缓存中都会有过期时间,这个过期时间需要在实践中去找到一个比较合适的时间,既能保证redis的命中率又要尽量保证是热数据。但是当前这个逻辑有个缺点:一旦去查询根本不存在的数据的时候,就出现了缓存被击穿的现象,就会不停的查库对外来说就好比没有加缓存一样。解决缓存被击穿的问题
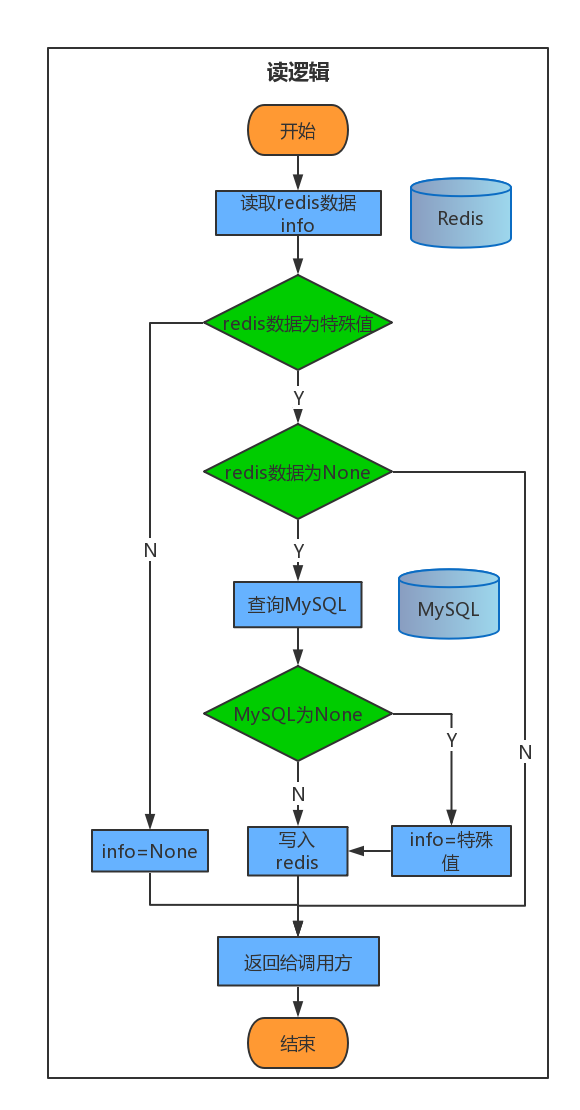
解释说明
该逻辑其实就是比上边的逻辑多了一层”特殊值的判断“,我们利用这样的特殊值来解决缓存击穿的问题,但是需要添加另外的维护成本:特殊值要绝对特殊,不能和有用数据重合;存放特殊值的key不能永久不变(尽量给一个较短的过期时间,因为有可能这个key之前不存在后来存在了,如果给的过期时间太长会造成数据的长时间不一致);当查到这种不存在的特殊key时尽量加上报警日志,也许有人在恶意攻击,我们要采取响应的措施去防范。`
总结
介于时间问题先写到这吧,这是我在工作中总结的一些经验,希望能对那些刚接触缓存的同学有一定的帮助作用。当然
缓存不一定就非要用redis,还有很多类似的产品,另外还可以用本机内存去实现,有兴趣的话可以自己玩一玩。以上
我整理的内容如果有不足的地方还请大家指出,相互交流。
