引言
之前分享了一篇如何提高django的并发能力文章,在文章的最后分享了进一步提升qps的方法,其中讲到了tornado,于是利用业余时间,折腾了一下nginx+tornado,当然和如何提高django的并发能力的业务模式一致。
为什么现在才分享: 其实之前就写完了,有一段时间没有在维护博客了,然后自己重新测试了一下,下边分享。
说明
还是利用上一篇文章如何提高django的并发能力的数据模型,这次以get一条数据为例。
- 服务器: 4核+4G (docker)
- 压测机: 4核+2G (docker)
- tornado: 5.1
- orm: yunorm (轻量级orm, 欢迎使用yumorm)
- msyql: 4核+4G(docker) max_connections:1000 max_user_connections:1000
- 数据库数据量: 50万条左右
不在介绍tornado的优势,直接说我折腾的过程
其他说明
架构: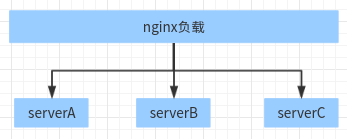
样例代码:
代码
orm: 采用了数据库连接池, 每个tornado 数据库 pool_size 为20
压测方式及命令
- 压测方式:

- 压测命令:
- ysab: ysab -n 500 -r 100 -u http://B_ip:8080/test'
- 备注: 欢迎使用ysab, ysab文档
nginx优化前
本次server起4个(个数和核心数一致)tornado进程
压测结果
qps
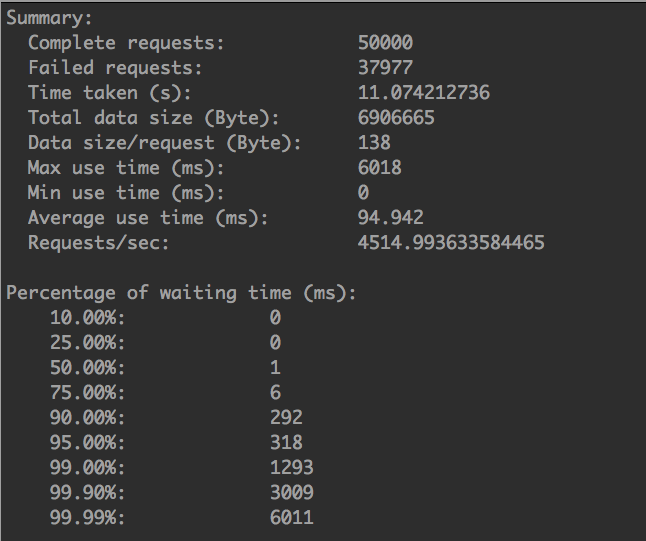
问题
不经意看,qps能提升这么多,仔细一看不是这么回事,注意看一下失败数将近38000条,有点蒙,为什么会有这么高的失败数,如果直接压测tornado server而不经过nginx,则不会出现这个问题。而且返回code如下所示:
Response Time histogram (code: requests):
200: 12023
502: 37977
全是502,看了(netstat -nptal|grep TIME_WAIT|wc -l)一下TIME_WAIT数,破两万,为什么会有这么多的WAIT数?
tornado数据库操作太慢?
去掉数据库操作代码,直接返回hello,先压测单个tornado server,qps有1200左右,没有502。
nginx+tornado(2个),又开始大片出现502,一坨TIME_WAIT。到这很明显了,不是tornado的问题。sysctl需要优化?
sysctl参数优化,这篇文章写的是真不错,其实目前是nginx配置问题导致,后边会说,即便nginx配置没有问题,sysctl优化也是有利于提升服务能力的。
优化完后没有太大改进,因为本身这些参数之前优化过和文章说的差不多。nginx优化
现在应该很明显了,就是nginx配置问题,这里边涉及到一个长连接的问题。
之前的配置:1
2
3
4
5
6
7
8
9
10
11
12upstream webapp {
server 127.0.0.1:8000;
server 127.0.0.1:8001;
server 127.0.0.1:8002;
server 127.0.0.1:8003;
}
server {
listen 80;
location / {
proxy_pass http://webapp/;
}
}
从nginx到server的连接不是长连接,导致每次请求nginx到server之间都会建立新的tcp连接,即便我们优化了net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
高并发下照样会出现一坨的TIME_WAIT,导致502的问题。
到这优化了,可以参考文章nginx长连接, 配置优化如下:
1 | upstream webapp { |
nginx优化后
后端4个tornado进程
- qps
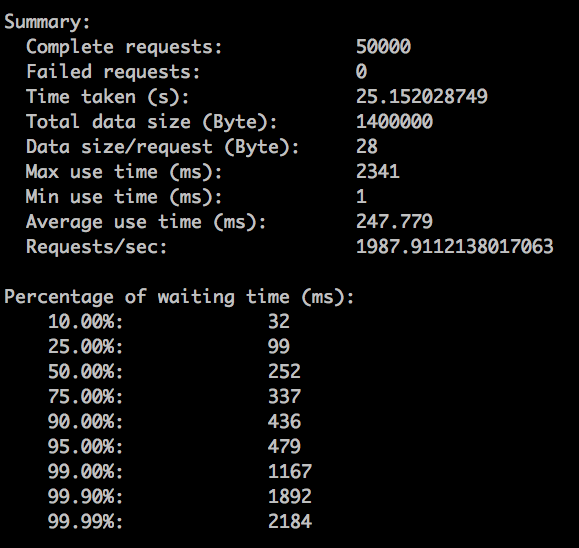
还是比较理想的,比之前的gunicorn+gevent+djangot有了700的提升
后端8个tornado进程
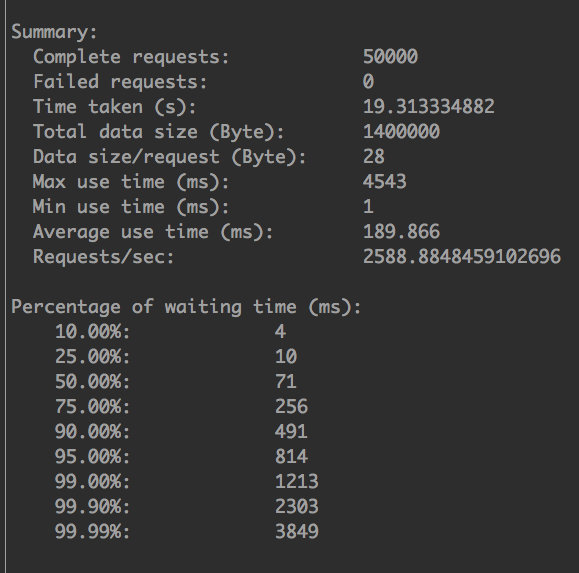
还是比较理想的,比后端4个tornado进程有了700的提升
总结
io密集型服务器的,相对于dajango tornado还是有很大的优势的,如果说基于Python开发,tornado还是一个非常好的选择。
关于tornado进程数个数,这里建议是2n(n为cpu核心数)个,当然这是一般情况,具体情况还需要具体分析压测一下。
