引言
之前分享了一篇如何提高django的并发能力文章,在文章的最后分享了进一步提升qps的方法,其中讲到了gin,下边在同样的业务场景分享一下压测数据。
说明
- 服务器: 4核+4G (docker)
- 压测机: 4核+2G (docker)
- Go: 1.11.4
- msyql: 4核+4G(docker) max_connections:1000 max_user_connections:1000
压测方式及命令
- 压测方式:

- 压测命令:
- ysab: ysab -n 500 -r 200 -u http://B_ip:8080/test'
- 备注: 欢迎使用ysab, ysab文档
数据表说明
| 字段名 | 类型 | 索引类型 |
|---|---|---|
| id | int(11) | PRI |
| name | varchar(40) | MUL |
| url | varchar(150) | |
| descp | varchar(50) | |
| zan_num | int(11) | |
| like_num | int(11) | |
| create_time | datetime(6) | MUL |
写压测
代码
随机写一条数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31view.go:
func FeedGet(c *gin.Context) {
// nt := time.Now().Nanosecond()
// id, _ := models.FeedZanGet(nt % 200000)
res, _ := uuid.NewV4()
t := time.Now().Unix()
st := strconv.FormatInt(t, 10)
name := res.String()
id, _ := models.FeedAdd(
name, stringAdd("http://", name),
stringAdd(name, st), int(t/10000), int(t/13000))
c.JSON(200, gin.H{
"code": 200,
"id": id,
})
}
util.go:
func FeedAdd(name, url, desc string, like_num, zan_num int) (id int64, err error) {
stm, err := db.MySQLCon.Prepare(
"insert into feed(name, url, descp, zan_num, like_num,create_time) values(?, ?, ?, ?, ?, ?)")
if err != nil {
return 0, err
}
defer stm.Close()
res, err := stm.Exec(name, url, desc, zan_num, like_num, time.Now())
if err != nil {
return 0, err
}
return res.LastInsertId()
}
压测数据
机器负载(几乎没什么负载)
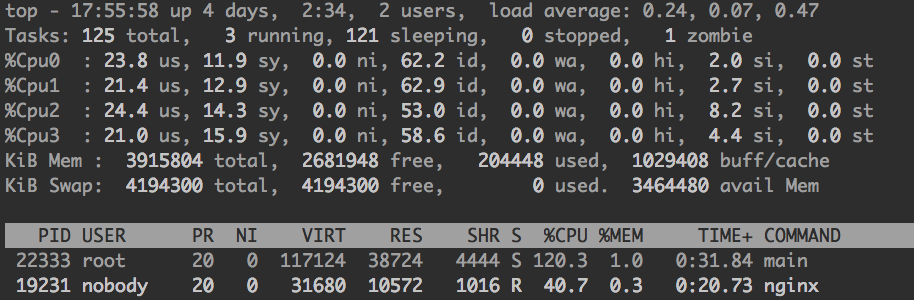
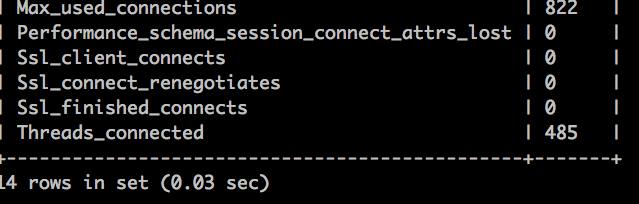
数据库连接数
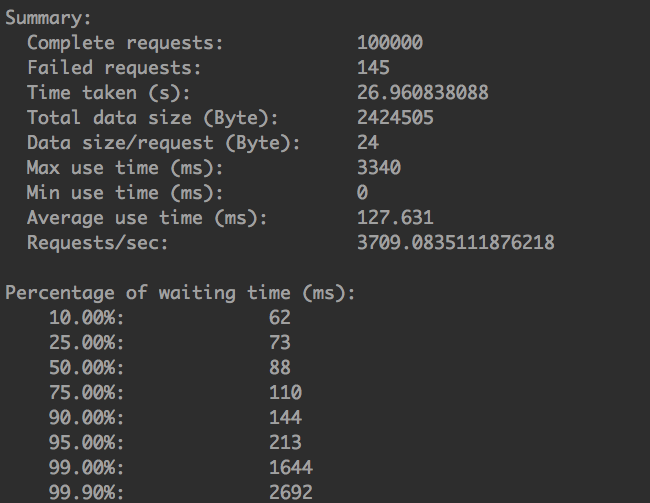
qps
读压测
场景说明
数据库表中大概有50万条数据, 随机取出一条数据,上边的代码里已有
压测数据
机器负载(几乎没什么负载)
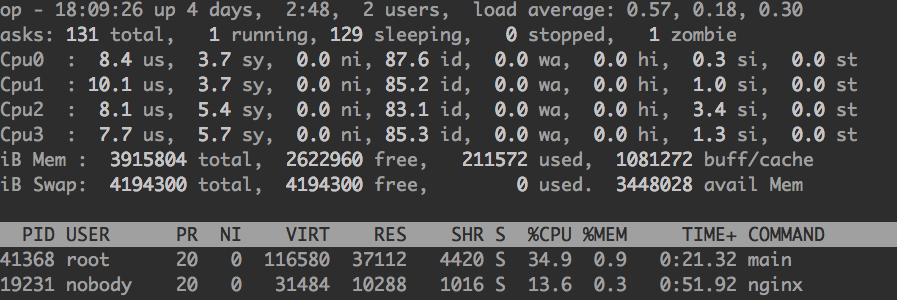
数据库连接数
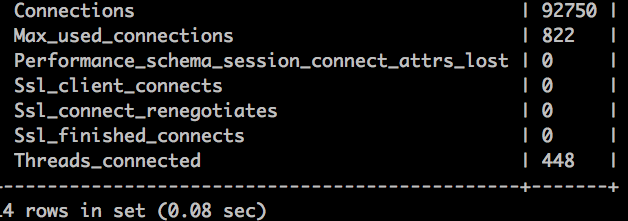
qps
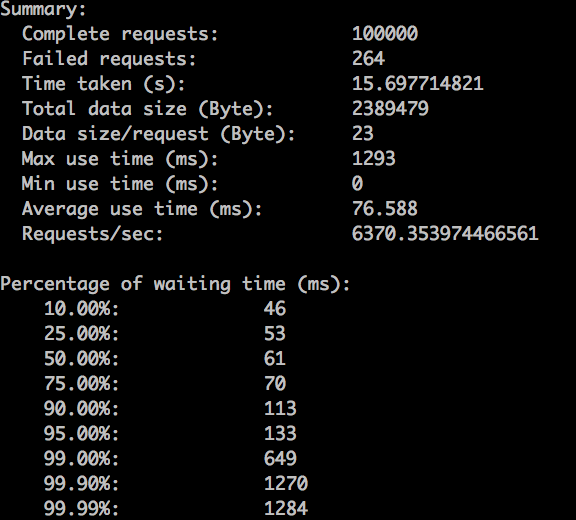
总结
Golang为什么会有这么好的性能,得益于goroutine以最低的耗损,充分利用多核,这里有一篇关于goroutine的说明。
当然不管选择python的Django还是Golang的gin,关键看业务场景,如果本身没有这么高的并发量,Django还是很合适的,尤其是在试探型项目,从0到1的开发,不得不说利用Django能非常快速的完成。当然量(io密集型)比较大了,由于CPython的GIL的制约,这时候需要考量一种编译语言了,Golang还是个不错的选择。
